Compressing multimodal and unimodal Transformers via UPop
TL;DR: UPop is the first structured pruning framework for vision-language Transformers. It enables effective structured pruning on various multimodal & unimodal tasks, datasets, and model architectures.
[Paper link] • [Code link] • [Project link]
Background
The notable improvement in recent AI models (e.g., Transformers¹) is at the expense of significantly increased computational cost, which makes compression exceedingly critical for deploying and using the increasingly heavier models on consumer-level devices. Although extensively studied for unimodal models (e.g., pruning, quantization, distillation, and other techniques for unimodal CV/NLP models), the compression for multimodal models (especially the vision-language Transformers), is still relatively under-explored. The goal of this blog is to briefly introduce a structured pruning method UPop for compressing vision-language Transformers.
Overview
What is it UPop is the first structured pruning framework for vision-language Transformers. It enables effective structured pruning on various multi-modal & uni-modal tasks (including Visual Reasoning, Image Captioning, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, Image Classification and Image Segmentation), datasets (including NLVR2, COCO Caption, VQAv2, COCO, Flickr30K, ImageNet and ADE20K), and model architectures (including BLIP², CLIP³, DeiT⁴ and Segmenter⁵).
What challenge does it tackle The above video demonstrates that Unified Search adopted by UPop rescues us from the burden of repeated experiments (e.g., doing grid search) for searching optimal compression ratios among different modalities and structures. Furthermore, Progressive Pruning adopted by UPop eliminates the weight gap between the searched model and the pruned subnet to be retrained, therefore gaining better convergence and performance, especially at high compression ratios.
How about the performance On multimodal tasks, for example, UPop can achieve 2x compression with only 1.2% and 2.0% accuracy loss on the VQAv2 dataset for Visual Question Answer and the NLVR2 dataset for Visual Reasoning, respectively. On unimodal tasks, for example, UPop can achieve 1.5x and 1.2x compression without any loss of accuracy on the ImageNet dataset for Image Classification and the ADE20K dataset for Image Segmentation, respectively. Some examples of vector-level structured granularity are as follows.

Method

1. Granularity of Pruning
UPop is implemented as a vector-level structured pruning method, i.e., the minimum pruning unit is an entire row or column of the parameter matrixes. Compared to unstructured pruning methods, vector-level structured pruning allows UPop to physically extract the pruned subnet from the original model (the parameter matrix is still legal after eliminating entire rows or columns, but unstructured pruning results in a different number of parameters to be pruned in each row or column, and thus the pruned parameters cannot form a legal matrix).
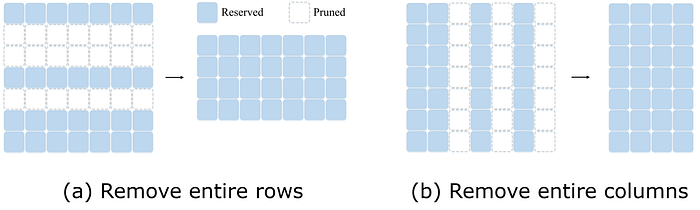
Overall, unstructured pruning has a finer granularity, so the accuracy of the pruned model will be relatively higher, but deployment will be relatively more difficult. Structured pruning, on the other hand, has a coarser granularity, so the accuracy of the pruned model will be relatively lower, but deployment will be simpler. The UPop method itself is not limited to a certain granularity, and the use of structured or unstructured to implement the pruning algorithm is actually a tradeoff between model accuracy and deployability, Therefore, it is only fair to limit the comparison to the same granularity when comparing the accuracy of pruned models.
2. Unified Search
The application of Unified Search tackles the first challenge that existed in the previous methods: When given a total compression ratio, we have to manually explore suitable compression ratios for different components in different modalities, which is inefficient, especially when the model has multiple types of modules (these modules may comprise Self-Attentions, Cross-Attentions, and Feed-Forward Nets in both vision and language branches for typical vision-language Transformers).
Let’s compare existing methods with Unified Search using a total compression ratio of 50% as an example:
2.1 Even assignments (Before)
A simple strategy is to assign the same compression ratio to all the different compressible modules in different modalities. However, in multimodal models, the optimal compression ratios for different modalities and modules may vary, and therefore even assignments are most likely sub-optimal.

2.2 Multiple grid searches for suitable assignments (Before)
A better strategy is to use repeated experiments (e.g., gird search) to test different assignments and choose the best one among them. However, the improvement in performance is at the expense of significantly higher time costs.

2.3 Unified Search for adaptive assignments (UPop)
Unified Search treats all compressible components in all modalities as a unified space, searches and ranks on them, accordingly outputs global compression assignments, and adaptively determines parameters to be pruned for different components in different modalities. Unified Pruning rescues us from the burden of repeated experiments (e.g., doing grid search) for searching the optimal compression ratio assignment.

The trick here is that before a unified ranking, a z-score standardization(subscripts a and m represent the Attention and FFN structures respectively) should be conducted on different structures:
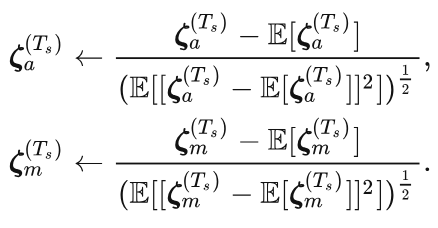
This is because the distribution of importance metrics can vary greatly across structures, and directly unified ranking can bias some structures, e.g., leading to a concentration of the vast majority of pruned parameters in Self-Attentions. The use of z-score standardization mitigates this bias.
3. Progressive Pruning
The application of Progressive Pruning tackles the second challenge that existed in the previous methods: After the search stage, unimportant neurons are going to be removed. However, many of them have non-zero weights, and suddenly binarizing them to zero after searching harms the convergence of the pruned subnet. In other words, the significant gap of parameter weights between the searched model (i.e., model after the searching stage) and the pruned subnet to be retrained cause it hard to converge and severely degrades the final performance.
Let’s compare existing methods with Progressive Pruning by pruning 50% of the model parameters as an example:
3.1 Prune all at once (Before)
A simple strategy is to prune the required total number of parameters at once. However, the model before and after pruning has a huge parameter gap as mentioned earlier, resulting in sub-optimal performance and worse convergence of the pruned model at high compression ratios.

3.2 Iterative Pruning for dividing pruning into multiple steps (Before)
A better strategy is to use Iterative Pruning⁶ to divide weights into multiple groups, and each time only binarize a smaller number of non-zero weights to 0, as demonstrated in the figure below. Iterative Pruning can reduce the parameter gap between the model before and after the pruning, and thus achieves a better performance compared to pruning all at once.

3.3 Progressive Pruning eliminates the parameter gap (UPop)
Iterative Pruning reduces the parameter gap between the model before and after pruning, while Progressive Pruning eliminates the parameter gap. Progressive Pruning not only divides the parameters into multiple groups but also divides the pruning process of each parameter into multiple rounds of small-step prunings to ensure that all the parameters to be pruned will exactly converge to 0 after searching, thus eliminating the parameter gap between the model before and after pruning. Progressive Pruning achieves better performance and convergence, especially at high compression ratios.

The trick here is to progressively shrink the parameter weights until they are 0. Typically the updating of the parameters in the model is controlled by the optimizer, e.g. using a regular gradient descent updating:
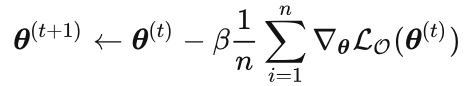
However, it does not satisfy our expectation, i.e., to freely control the value of the parameter weights at each iteration t. For example, we want to shrink a parameter with an initial value of 1 to exact 0 after 100 iterations:
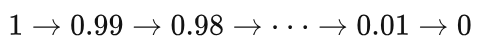
So here we need to use a custom rule for partial parameter updates. Specifically, we use the regular optimizer to update the original parameters of the model, and use a custom rule to update the parameters of the learnable masks inserted into the model. For example, in each time step t, the current expected compression ratio to be achieved is first updated (where p is the final compression rate to be achieved and T_s is the total number of iterations in the search stage):
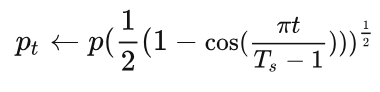
Here we use a cosine update strategy described above will work better than the uniform update strategy. And then the current weight positions to be pruned can be determined by a unified ranking:
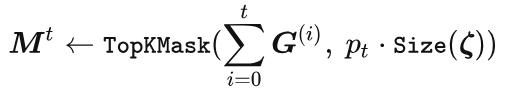
Finally, the parameter weights are updated for the current time step t:
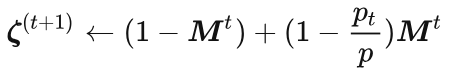
4. Algorithm Implementation

The proposed UPop framework combines Unified Pruning and Progressive Pruning as outlined in Algorithm 1. Line 2 ∼ 12 implements the search phase where Line 10 calculates the current compression ratio p_t to be achieved, and Line 13 ∼ 15 implements an optional retrain phase. More details can be found in the original paper and code.
Experiments
UPop supports various multi-modal & uni-modal tasks (including Visual Reasoning, Image Captioning, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, Image Classification and Image Segmentation), datasets (including NLVR2, COCO Caption, VQAv2, COCO, Flickr30K, ImageNet and ADE20K), and model architectures (including BLIP, CLIP, DeiT and Segmenter).
1. Compress BLIP on the NLVR2 dataset of the Visual Reasoning task
The marker √ or × indicates whether the model converges at the current compression times. The units of Params and FLOPs are M and G, respectively. The following table demonstrates that UPop can achieve superior performance at the same compression ratios and gains better convergence at higher compression ratios.
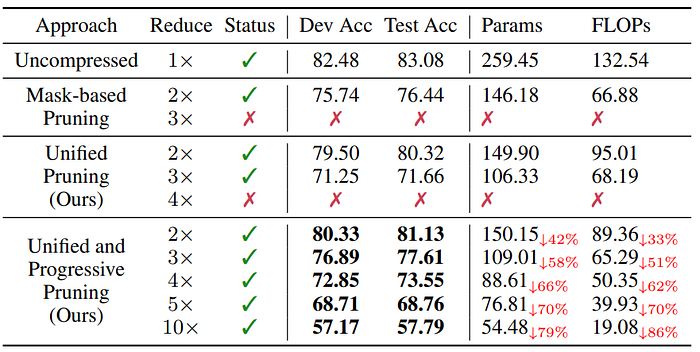
2. Compress BLIP on the COCO Caption dataset of the Image Captioning task and the VQAv2 dataset of the Visual Question Answering task
Notations are the same as in the above table. The CIDEr and SPICE are the higher the better. The table below demonstrates the good versatility of UPop across different tasks and datasets.

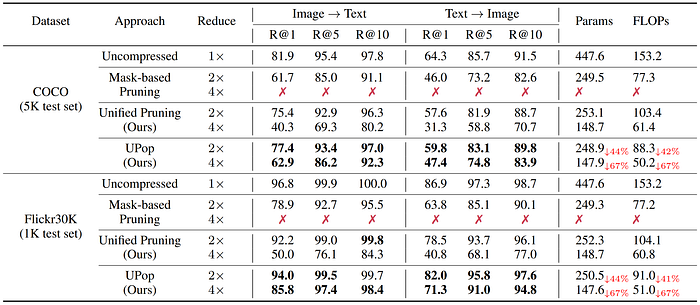
3. Compress BLIP on the COCO and Flickr30K datasets of Image-Text Retrieval and Text-Image Retrieval tasks
Notations are the same as in the above table. The R@1, R@5, and R@10 are the higher the better. The table below further demonstrates the good versatility of UPop across different tasks and datasets.
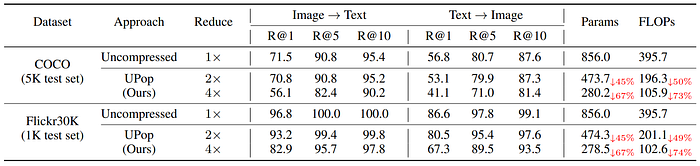
4. Compress CLIP on the COCO and Flickr30K datasets of Image-Text Retrieval and Text-Image Retrieval tasks
Notations are the same as in the above table. The table below demonstrates the good versatility of UPop across different model architectures.
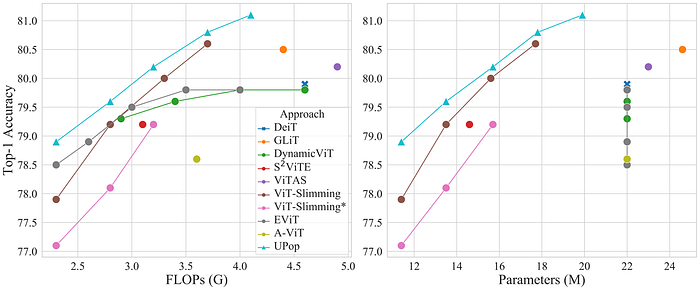
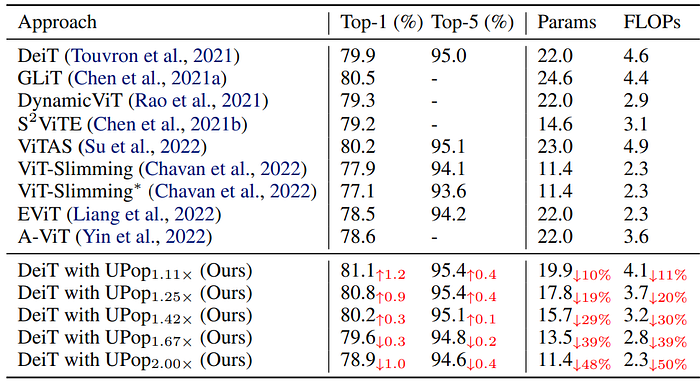
5. Compress DeiT on the ImageNet dataset of Image Classification task
It is worth mentioning that although experiments of UPop are mainly conducted on multimodal Transformers, the paper also reports performance on unimodal tasks. As shown by the blue triangles in the following Accuracy-FLOPs and Accuracy-Parameter trade-off figures, UPop can also achieve competitive performance compared to other unimodal compression SOTA approaches.
6. Compress Segmenter on the ADE20K dataset of Image Segmentation task

Experimental results above demonstrate: (1) When comparing the model pruned by UPop with the uncompressed model, UPop can achieve more than 1.2× loss-free compression and around 1.4× compression with less than 1% mIoU loss for both single-scale and multi-scale testing. (2) When comparing the model pruned by UPop with other models with similar params/FLOPs, UPop can achieve very competitive performance under Performance-Parameters and Performance-FLOPs trade-off constraints. For example, the 1.1× compressed model can outperform all other models on multi-scale testing, and achieve a second place on single-scale testing by only using 54% FLOPs of the first place model. (3) When comparing UPop’s performance on the semantic segmentation task with on the image classification task (refers to Appendix Table 16), UPop can achieve around 1.5× loss-free compression and 2× compression with no more than 1% accuracy loss on the image classification task. We believe this ratio gap should be attributed to the intrinsic properties of different tasks. For example, classification models have more redundancy since many pixels (e.g., background pixels) are unimportant for classification results, and therefore classification models can be pruned more easily. On the other hand, segmentation models have less redundancy since the model is expected to output the corresponding category for each pixel, and therefore pruning segmentation models is more difficult.
7. Variation of compressible components in different modalities as the compression ratio increases
The figure below shows that the retained percentage of Self-Attention of ViT and Self-Attention of Bert among all compressible components significantly increases as the compression ratio increases. In contrast, the retained percentage of MLP of ViT and MLP of Bert decreases. This indicates that Self-Attentions have higher importance than MLPs when the number of parameters is limited. It can also be observed that vision modality is more important than language modality in this task. The trend of the retained percentage of Cross-Attention generally decreases and then increases. This phenomenon indicates that at low compression ratios, the parameters of the visual and language modalities are relatively adequate. Therefore cross-attention is less important at this time. At high compression ratios, the vision and language modality lacks sufficient parameters, and cross-attention becomes more critical.
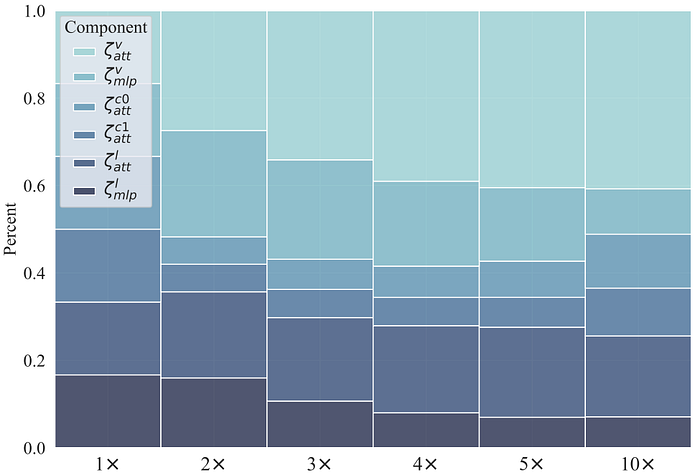
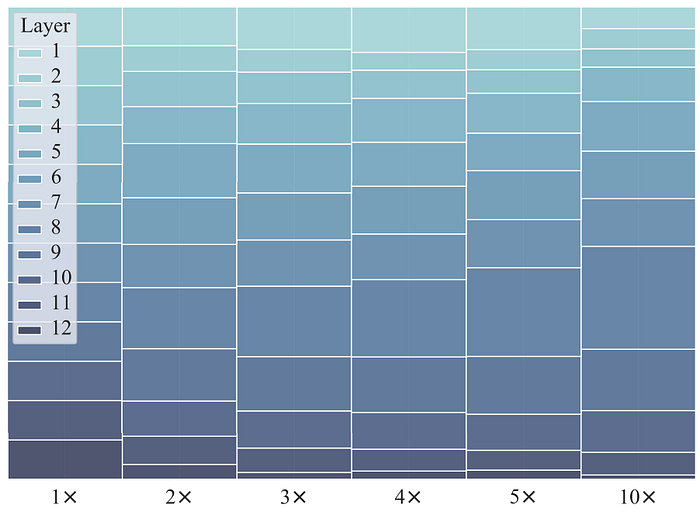
8. Variation of layers as the compression ratio increases
Similarly, the figure below demonstrates the variation of all layers as the total compression ratio increases. It can be observed that the middle layers occupy an increasing proportion as the total compression ratio increases, which indicates that the majority of modalities’ information is generated in the middle layers of the model. In the earlier layers, the information is not detailed enough. In contrast, in the last several layers, the refinement of the information becomes less critical when the number of parameters is limited.
More experiments and analyses can be found in the original paper and code.
Summary
UPop is a universal structured pruning framework that supports a wide range of multi-modal & uni-modal tasks, datasets, and model structures. It is also the first framework to support structured pruning for Vision-Language Transformers. UPop has the advantages of more efficient search, adaptive compression assignments for better performance, elimination of the parameter gap before and after pruning, and better convergence at high compression ratios. Thorough experiments demonstrate the effectiveness and versatility of UPop.
References
- Attention is All you Need. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. https://proceedings.mlr.press/v162/li22n/li22n.pdf
- Learning Transferable Visual Models From Natural Language Supervision. https://arxiv.org/pdf/2103.00020.pdf
- Training data-efficient image transformers & distillation through attention. https://arxiv.org/pdf/2012.12877.pdf
- Segmenter: Transformer for Semantic Segmentation. https://openaccess.thecvf.com/content/ICCV2021/papers/Strudel_Segmenter_Transformer_for_Semantic_Segmentation_ICCV_2021_paper.pdf
- Learning both Weights and Connections for Efficient Neural Networks. https://proceedings.neurips.cc/paper/2015/file/ae0eb3eed39d2bcef4622b2499a05fe6-Paper.pdf
